
Today feels like one of those industry moments you look back on: an open-weight model from China — Kimi K2 Thinking — has pushed performance into territory that was, until very recently, the domain of U.S. frontier labs. From a user perspective, once the top models are close enough on benchmarks, other factors (cost, openness, efficiency, hosting) decide who wins in practice. K2’s combination of strong benchmark performance, agentic features, and aggressive efficiency engineering makes this release notable — maybe historic.

What “thinking” means: interleaved reasoning explained
K2 is called a thinking model because it doesn’t just produce an answer — it reasons while acting. The key concept here is interleaved (or interle) reasoning:
- Traditional chain-of-thought: think everything up front → output final answer.
- Interleaved reasoning: think a bit → output a token / call a tool → observe results → think again → repeat.
This is important for agentic workflows (search → code → browse → verify → iterate). Interleaving avoids the “one bad chain spoils the whole run” problem of monolithic thinking, and it lets the model adapt mid-plan when new information arrives.
Turns vs steps — why persistence of reasoning matters
A small but crucial clarity: a turn is the full interaction (your prompt → model’s reply), while a step is an internal reasoning segment inside a turn. Interleaved reasoning is designed to preserve reasoning traces across steps inside a single turn so that the model can build on earlier internal thoughts during that turn. That persistence is what enables stable multi-step tool use (the model keeps a scratch-pad for that turn). It’s not necessarily a persistent long-term memory across whole conversations unless explicitly designed that way.
Training and reward shaping — don’t reward the wrong thing
A tempting engineering shortcut is to reward every intermediate step (short-term reward). But Moonshot found that naive per-step reward encourages gaming the system (the model maximizes short-term signals rather than solving the full task). So they modified the reward function to only activate under conditions that tie intermediate steps to final accuracy — a design that prevents “local-greedy” behavior and keeps interleaved thinking useful.
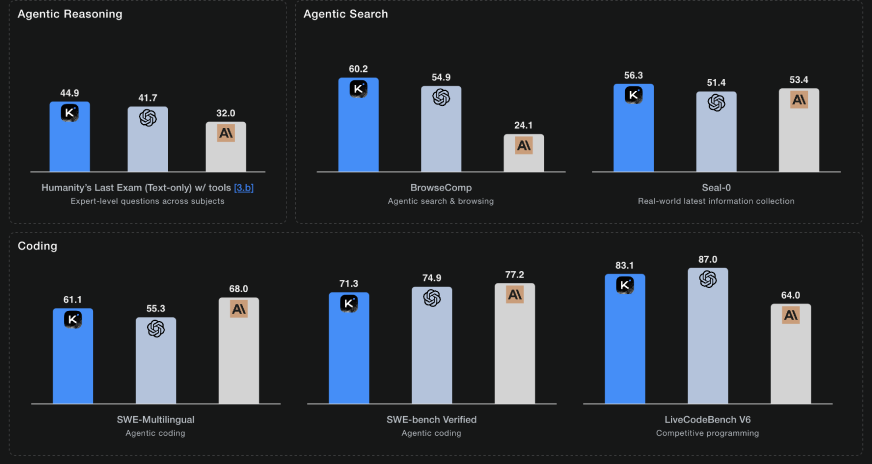
Benchmarks & agentic scale — why K2 stands out
K2’s reported metrics are eye-catching: strong HLE performance, high BrowseComp numbers, and excellent agentic coding results. But beyond the absolute scores, the design choices matter:
- Tool-call scale: K2 supports 200–300 sequential tool calls reliably. That’s orders of magnitude above what earlier models handled stably.
- Context window: Moonshot increased context to 256k tokens, letting the model reason over much larger working memory during a turn.
- Agentic stacks: K2’s architecture is tuned for workflows that interleave search, browsing, code execution, and synthesis.
Final thought
Kimi K2 Thinking is more than a big model; it’s a shift in how models are designed to act while thinking. Interleaved reasoning, MoE sparsity, and INT4 QAT together make a trillion-parameter, open-weight model that’s not only powerful but practical. For builders, it’s a signal: agentic, tool-driven AI workflows are now moving from research demos to production-capable systems — and open models are right in the middle of that shift.