A lot of developers felt something strange recently.
Claude Code, which many people use every day for serious engineering work, started feeling worse.
Not completely broken.
Just different.
Less sharp.
More forgetful.
More repetitive.
Less reliable on complex coding tasks.
And for a while, nobody knew whether this was just a feeling, a model regression, a usage limit issue, or some silent product change.
Then Anthropic published a post-mortem.
The important part?
The model itself was not the main problem.
The issue was the product layer around the model.
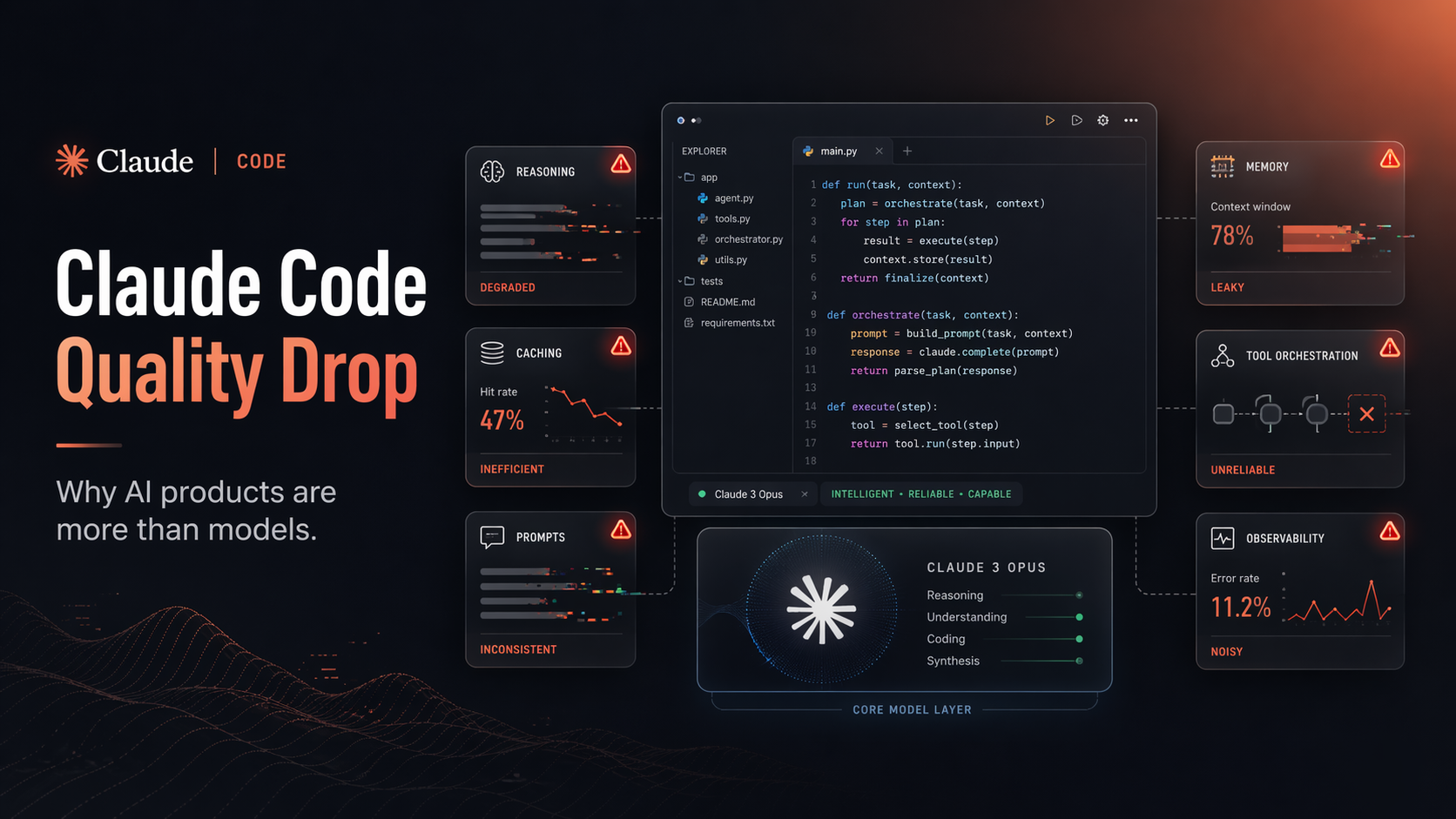
Anthropic traced the Claude Code quality drop to three separate changes: a default reasoning effort change, a caching bug, and a system prompt change that tried to reduce verbosity. The API and core inference layer were not impacted, and all three issues were resolved by April 20, 2026 in v2.1.116.
This is a very useful lesson for anyone building AI products.
Because in production AI, the model is only one part of the system.
The real product is everything around it.
What Actually Happened?
Anthropic found three main issues.
The first issue was a reasoning effort change.
Claude Code’s default reasoning effort was changed from high to medium to reduce latency. This made sense on paper. Faster responses. Less waiting. Lower usage burn.
But for complex coding tasks, that tradeoff hurt quality.
The model was thinking less, so users felt it was less intelligent.
The second issue was a caching bug.
Anthropic added logic to clear older reasoning from sessions that had been idle for more than an hour. The idea was to reduce latency when users resumed long sessions.
But a bug caused this clearing to happen again and again on every turn.
So Claude started losing the reasoning trail behind its own work.
That is a big deal in coding.
When an AI agent is editing files, running commands, reviewing output, and making decisions across multiple steps, continuity matters. If it forgets why it made earlier choices, the work starts becoming messy very quickly.
The third issue was a system prompt change.
Anthropic added instructions to make Claude Code less verbose. The goal was reasonable. Nobody wants unnecessary walls of text between every tool call.
But the change went too far.
The output became shorter, and coding quality dropped on evaluations.
This is one of the most interesting parts of the incident.
Sometimes verbosity is not just verbosity.
Sometimes it is reasoning space.
Sometimes a few extra lines are what allow the model to explain, plan, check assumptions, and avoid shortcuts.
The Bigger Lesson
This incident was not just about Claude Code.
It is about how fragile AI products can become when small product decisions compound.
A model can be excellent.
But the final user experience can still degrade because of:
- Bad defaults
- Overaggressive latency optimization
- Poor context handling
- Weak eval coverage
- Prompt changes without enough testing
- Caching logic that looks harmless but breaks continuity
- Product updates that optimize for cost instead of output quality
This is why shipping AI products is very different from just calling an API.
A good AI product needs strong engineering around the model.
It needs evals.
It needs observability.
It needs careful rollout systems.
It needs real user feedback loops.
It needs prompt versioning.
It needs regression testing.
It needs people who understand both software engineering and model behavior.
Without that, small optimizations can quietly turn into product regressions.
Why This Matters For Founders And Teams
A lot of companies are adding AI features right now.
Some are building internal copilots.
Some are building customer support agents.
Some are building AI workflow tools.
Some are building coding agents.
Some are adding AI automation into existing SaaS products.
The common mistake is assuming the model will carry the product.
It will not.
The model can give you intelligence, but the system gives you reliability.
And users do not judge your AI product by the benchmark score of the model behind it.
They judge it by what happens in their workflow.
Does it remember context?
Does it handle edge cases?
Does it fail safely?
Does it produce consistent results?
Does it get worse after an update?
Does it explain enough without overwhelming the user?
Does it know when to ask for input?
Does it stay useful when the task becomes complex?
That is the real test.
What AI Builders Should Take Away
The Claude Code incident gives us a simple checklist.
When building an AI product, do not only ask:
“Which model should we use?”
Ask:
“What happens when the model is used inside a real product?”
That means checking:
- Prompt changes before and after release
- Context retention across long sessions
- Latency versus quality tradeoffs
- Tool use reliability
- Regression after updates
- Output quality across different task types
- User feedback patterns
- Cost optimization side effects
- Failure modes in complex workflows
This is where serious AI engineering begins.
Not at the model selection layer.
At the product reliability layer.